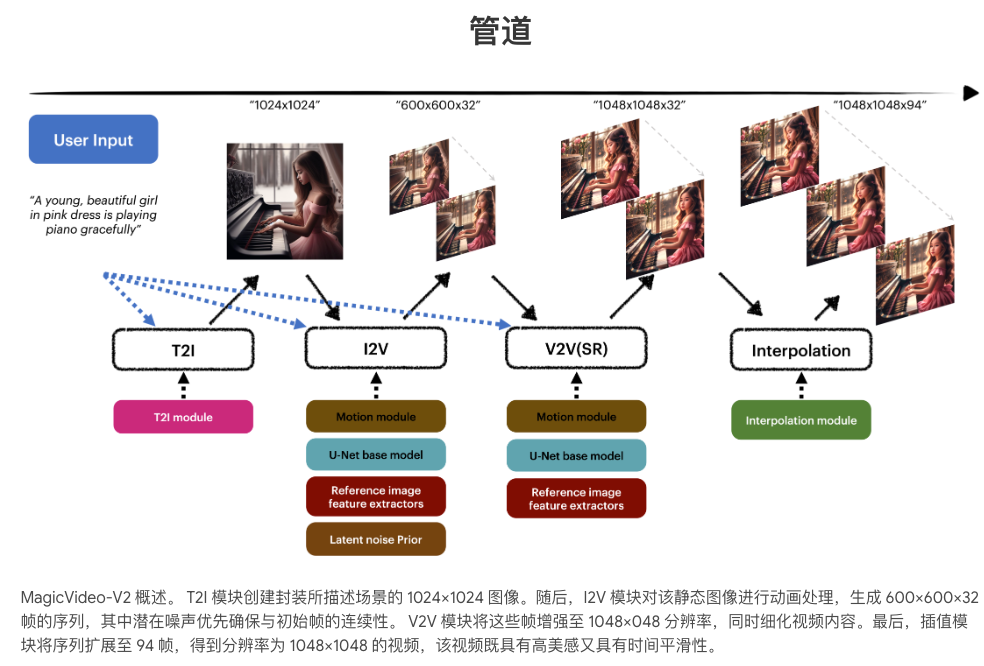
综述
MagicVideo-V2 是
字节跳动公司开发的一款 AI 视频生成工具,它具有以下特点:
- 高保真度和流畅性:可以生成具有高审美品质和时间平滑性的高分辨率视频。
- 先进的架构设计:集成了文本到图像模型、视频运动生成器、参考图像嵌入模块和帧插值模块。
- 超越其他视频模型:MagicVideo-V2 可以生成具有出色保真度和平滑度的美观、高分辨率视频。通过大规模用户评估,它表现出了优于 Runway、Pika 1.0、Morph、Moon Valley 和 Stable Video Diffusion 模型等领先文本转视频系统的性能。

从上图可见,这个系统的核心模块有四块T2I,I2V,V2V(超分),插帧四个模块,下面我们分别展开:
文本到图像(Text-to-Image, T2I)模块:
它接收用户输入的文本提示,并生成一个1024×1024像素的参考图像。这个参考图像对于描述视频内容和确定视频的审美风格至关重要。MagicVideo-V2 设计为兼容不同的T2I模型,这意味着它可以与多种不同的文本到图像生成技术结合使用。
在MagicVideo-V2中,特别采用了“字节跳动公司”内部开发的基于扩散模型(diffusion-based)的T2I模型。
这种模型能够输出具有高审美价值的图像,即生成的图像不仅在视觉上吸引人,而且在艺术风格上也与文本描述相匹配。这种模型的集成使得MagicVideo-V2能够在视频生成过程中,从一开始就确保图像的质量和风格与用户的期望相符。
图像到视频(Image-to-Video, I2V)模块:
I2V(图像到视频)模块是MagicVideo-V2系统中的一个关键部分,它建立在一个高审美的SD1.5模型之上。这个模型通过利用人类反馈来提高视觉质量和内容一致性。I2V模块添加一个的运动模块来扩展这个高审美的SD1.5模型。
为了更好地利用参考图像,I2V模块增加了一个参考图像嵌入模块。具体来说,它使用外观编码器(appearance encoder)来提取参考图像的Embedding,并通过交叉注意力机制(cross-attention mechanism)将这些Embedding注入到I2V模块中。这样做可以有效地将图像提示与文本提示解耦,提供更强的图像条件。此外,还采用了潜在噪声先验策略(latent noise prior strategy)来为起始的噪声潜在空间提供布局条件。通过这种策略,可以从标准高斯噪声初始化帧,其均值从零向参考图像潜在值偏移,从而部分保留图像布局并提高帧之间的时间连贯性。
为了进一步增强布局和空间条件,系统部署了一个ControlNet模块,直接从参考图像中提取RGB信息并应用于所有帧。这些技术有助于将帧与参考图像对齐,同时允许模型生成清晰的运动。
视频到视频(Video-to-Video, V2V)模块:
V2V(视频到视频)模块在设计上与I2V模块相似,共享相同的基础架构和空间层。这个模块专门针对视频超分辨率进行了微调,使用了高分辨率视频子集来训练其运动模块。这意味着V2V模块能够处理更高分辨率的视频帧,从而生成更清晰、更详细的视频内容。
在这个过程中,图像外观编码器(image appearance encoder)和ControlNet模块也被用于V2V模块。这些组件对于在高分辨率下生成视频帧至关重要。它们利用参考图像的信息来指导视频扩散步骤,这有助于减少结构性错误和失败率,同时增强在更高分辨率下生成的细节。
通过这种方式,V2V模块能够确保视频帧在保持与参考图像一致性的同时,还能在更高的分辨率下展现出更好的视觉质量。这种设计使得MagicVideo-V2能够在生成视频时,不仅在视觉上保持连贯性和吸引力,还能在细节上达到更高的标准。
视频帧插值(Video Frame Interpolation, VFI)模块:
VFI(视频帧插值)模块是MagicVideo-V2系统中用于平滑视频运动和生成高分辨率、平滑视频的关键部分。这个模块基于字节跳动公司内部训练的基于生成对抗网络(GAN)的VFI模型。它采用了增强型可变形分离卷积,其设计旨在提高视频帧插值的效率和质量。
为了进一步提升VFI模块的稳定性和平滑性,系统还使用了一种预训练的轻量级插值模型。它专门设计用于在保持视频帧连贯性和细节的同时,减少运动中的不自然跳跃和抖动。通过这种方式,VFI模块能够在关键帧之间进行有效的帧插值,生成连续且视觉上平滑的视频序列。